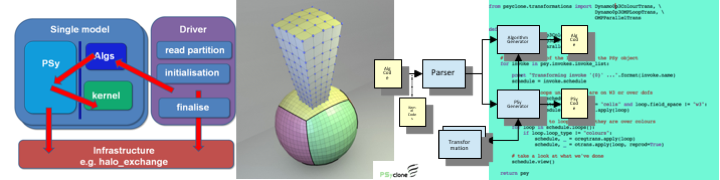
LFRic and PSyclone
In the absence of processor speed increases, performance gains can only come through parallelism. MPI is the standard library for distributed memory which can be called through an API from science code. This allows a relatively straightforward data parallelism to be expressed in the code without too much disruption to the maths/science code. However, this is no longer enough to address the degree of parallelism and does not allow for memory hierarchies and highly threaded parallelism on complex nodes. Directive based programming such as OpenMP or OpenACC can be used but these are developing rapidly and as the number of necessary directives increases it can obscure the science code. Moreover, having multiple directive groups for different architectures effectively prevents single source science code. Furthermore, future processor architectures are likely employ much greater levels of Instruction Level Parallelism. This may require different loop orders for different architectures which is beyond the scope of directives based programming models. The powerful abstraction of a high-level language and compiler which allows the developer to write code like the maths (in some sense) is broken.
Domain Specific Languages (DSLs) are one approach to tackling this problem. By reducing the domain from, for example, all of mathematics, to targeting a particular problem it is possible to split the mathematics based science code from the performance based parallel code. This is known as a separation of concerns. Once a code is structured in this way with well defined APIs between each concern it is possible to change one, without changing the other.
A further step is to use the extra information about the mathematics which is known to the developer to make choices about how the parallelism can be implemented. Typically this is known to the developer, but cannot necessarily be inferred by a standard language compiler. This can be expressed as metadata. If this is embedded in a high-level language such as C/C++, Fortran or Python then the APIs form in effect a Domain Specific Embedded Language (DSEL). If the metadata is sufficiently rich it is possible to generate the parallel and performance code automatically according to a set of rules.
This is approach being taken by the UK Met Office in developing its new weather and climate model for Exascale computers. The model is known as LFRic, named after Lewis Fry Richardson, who attempted the first numerical weather prediction 100 years ago and moreover, recognised the parallelism in the problem.
LFRic
The Met Office Science Repository Service for the LFRic Project
PSyclone
The Hartree Centre, at STFC Daresbury is partnering with the Met Office to develop the code parser, tranformer and code-generator called PSyclone. The git hub repository for PSyclone, the parser and code generator.
DSL Research
Whilst the development has been successful so far, there is still much work to be done to deliver a performance portable model and allow science developers to be productive. Moreover, computer science research needs to be done to understand how to proceed. In particular three big questions need to answered:
- How do we express the parallelism and data dependencies of the mathematics in the code?
- Once the code has been parsed and is in the form of an Intermediate Representation (IR), what transformations on the IR are need to obtain the necessary performance and optimisations?
- Rather than generating high-level langauge code which is then compiled to machine code by a standard compiler, can the the data be coupled via the IR to other compiler technologies such as LLVM or the OMNI compiler. Thus in effect becoming a Domain Specific Embedded Compiler?
Can this approach be extended to other codes, how big and what should be the domain of the DSL? Verification of science codes is an important topic, however, even those projects with good process who employ testing as part of the development still tend to employ some form comparison to known good answers. Can formal verification method use the IR of a DSL to produce correct programs?
People
